

Discover how Multimodal AI is revolutionizing the way we interact with technology by integrating multiple forms of data to create more intuitive and efficient systems. Multimodal AI integrates various data types such as image, text, and speech and combines them to achieve better results using multiple intelligent algorithms.
Understanding the Basics of Multimodal AI
Multimodal AI encompasses artificial intelligence systems that can simultaneously process and comprehend multiple data types. In contrast to traditional AI, which might concentrate on a single input form like text, images, or audio, multimodal AI combines these diverse data types to offer a more holistic understanding of information. This ability enables more refined and precise interpretations, making it particularly valuable in intricate scenarios where single-mode data might be insufficient.
By utilizing various data modalities, these AI systems can produce outputs that are richer and more contextually informed. For instance, a multimodal AI could assess a video by integrating visual data (the images), audio data (the sounds), and textual data (subtitles or spoken words) to create a more comprehensive and accurate depiction of the scene.
Multimodal AI is an advanced form of artificial intelligence that simultaneously integrates and processes different data types, including text, images, audio, and video. This capability enables it to generate insights, make predictions, and create content in a manner that simulates human perception and understanding. Here's what you need to know about multimodal AI:
Definition of Multimodal AI
Multimodal AI refers to systems that can analyze and interpret various modalities of data at the same time. Unlike traditional single-modal AI, which focuses on one type of data (e.g., only text or only images), multimodal AI combines different data types to achieve a more nuanced understanding of information. This integration enables the system to perform complex tasks that require context from multiple sources
How Multimodal AI Works
Multimodal AI is an advanced form of artificial intelligence that integrates and processes multiple types of data—such as text, images, audio, and video—to generate more comprehensive insights and responses. Here’s how multimodal AI works, based on the key components and processes involved:
1. Input Module
Data Collection: The input module gathers data from various modalities. This can include:- Text from documents or conversations.
- Images from cameras.
- Audio from recordings.
- Video from sensors
Preprocessing: Each type of data undergoes preprocessing steps such as normalization, cleaning, and feature extraction to prepare it for analysis. This ensures that the data is in a suitable format for further processing.
2. Fusion Module
Data Fusion Techniques: The fusion module combines the processed data from different modalities into a unified representation. Common techniques include:- Early Fusion: Combines raw data or features at the initial stages, allowing the model to learn from each data source simultaneously.
- Intermediate Fusion: Merges modalities during preprocessing, leveraging some shared learning across modalities while preserving modality-specific features.
- Late Fusion: Processes each modality separately and combines their outputs at the decision-making stage, allowing for more specialized handling of each data type.
3. Processing and Analysis
Deep Learning Models: The fused information is analyzed using deep learning algorithms tailored to handle various types of data:- Convolutional Neural Networks (CNNs) for image processing.
- Recurrent Neural Networks (RNNs) for sequential data like text or audio.
These models extract patterns and relationships within the integrated data, enabling a deeper understanding than what is possible with individual modalities.
4. Output Module
Result Generation: After processing, the output module generates results based on the fused multimodal representation. This can include:- Textual responses.
- Visual content.
- Predictions or classifications relevant to the task at hand.
5. Training and Fine-Tuning
- Multimodal AI systems are trained using labelled datasets that encompass various modalities. The training process involves learning the relationships between different types of data to improve predictive capabilities.
- Fine-tuning adjusts model parameters to optimize performance for specific tasks or datasets.
6. Contextual Understanding
One of the significant advantages of multimodal AI is its ability to understand the context by recognizing patterns across different types of inputs. For example, combining visual data with spoken language can enhance conversational systems by providing more human-like responses.
Multimodal AI works by integrating multiple types of data through a structured process involving input collection, fusion, processing, and output generation. By leveraging advanced deep learning techniques and effective fusion strategies, multimodal AI systems can provide richer insights and more accurate predictions than traditional unimodal systems, making them valuable across various applications such as healthcare, autonomous vehicles, and human-computer interaction.
Advantages of Multimodal AI
- Improved Accuracy: By leveraging multiple data sources, multimodal AI can achieve higher accuracy in predictions and analyses compared to single-modal systems
- Enhanced Context Comprehension: The ability to analyze various types of data simultaneously allows for a richer understanding of context, leading to more accurate insights and responses
- Natural Interaction: Multimodal AI facilitates more intuitive human-computer interactions by enabling users to communicate through different modalities (e.g., voice commands combined with visual inputs)
- Robustness Against Noise: These systems are more resilient to noise and variability in input data, as they can rely on alternative modalities if one source is compromised
- Capability Enhancement: The integration of diverse data types empowers multimodal AI systems to perform a wider range of tasks with greater accuracy. This broader understanding enables smarter decision-making based on comprehensive situational awareness.
- Efficient Data Utilization: Multimodal models can be trained with smaller amounts of data from various sources, making them more efficient compared to unimodal models that require large datasets from a single modality. This efficiency is particularly beneficial in scenarios where data collection is challenging.
- Enhanced Content Creation: Multimodal AI enables the generation of complex and rich content by integrating different types of data (e.g., text, images, audio). This capability is particularly useful in creative fields such as multimedia production and marketing.
- Cross-Modal Insights: By analyzing interactions between different data types, multimodal AI can provide deeper insights that would be difficult to achieve with unimodal systems. For instance, it can assess patient images alongside medical histories for improved diagnostic accuracy in healthcare settings
- Versatile Applications: Multimodal AI can be applied across various industries—from healthcare (analyzing medical images alongside patient records) to customer service (understanding queries through text and voice) and beyond
The advantages of multimodal AI—ranging from improved accuracy and context comprehension to enhanced user interaction and robustness—make it a powerful tool across various industries. By integrating multiple data types, these systems not only mimic human cognitive abilities but also provide richer insights and more effective solutions for complex challenges.
Applications of Multimodal AI
Multimodal AI has a wide range of applications:
- Image Captioning: Generating descriptive captions for images based on visual content.
- Speech Recognition: Combining audio input with visual cues (like lip movements) for better accuracy.
- Virtual Assistants: Understanding and responding to user commands that involve both text and voice inputs.
- Content Creation: Creating videos or multimedia presentations that integrate text, audio, and visuals seamlessly
Multimodal AI represents a significant advancement in artificial intelligence by enabling systems to process and understand complex information from diverse sources. This capability not only enhances the accuracy and robustness of AI applications but also fosters more natural interactions between humans and machines. As technology continues to evolve, multimodal AI is poised to play a pivotal role in shaping future innovations across various sectors.
Technologies Associated with Multimodal AI
Multimodal AI is an advanced field of artificial intelligence that integrates and processes multiple types of data—such as text, images, audio, and video—to enhance understanding and interaction. Here are the key technologies associated with multimodal AI:
Key Technologies in Multimodal AI
1. Input Module
The input module serves as the system's "nervous system," responsible for ingesting and processing different types of data. It normalizes various data formats to ensure compatibility with the AI model. This module typically consists of multiple unimodal neural networks, each specialized for a specific type of data (e.g., speech recognition, image analysis).2. Fusion Module
The fusion module combines and aligns data from different modalities into a cohesive dataset. Techniques used in this module include:- Transformer Models: These are advanced architectures that help in aligning and fusing data from various sources, enhancing the model's ability to understand complex relationships.
- Graph Convolutional Networks: These networks can process data represented as graphs, allowing for more nuanced integrations of multimodal information.
3. Natural Language Processing (NLP)
NLP technologies enable multimodal AI systems to understand and generate human language. This includes capabilities such as:- Speech Recognition: Converting spoken language into text.
- Text-to-Speech: Synthesizing spoken language from text.
- Sentiment Analysis: Understanding emotional tones by analyzing vocal inflections and facial expressions.
4. Computer Vision
Computer vision technologies allow AI systems to interpret visual data, including:- Object Detection: Identifying and classifying objects within images or videos.
- Facial Recognition: Recognizing individuals based on facial features.
- Activity Recognition: Understanding actions depicted in visual data (e.g., running, jumping).
5. Audio Processing
This technology focuses on interpreting audio signals for various applications, such as:- Speech Analysis: Understanding spoken language nuances, including tone and pitch.
- Music Retrieval: Identifying and categorizing music based on audio features.
6. Integration Systems
These systems are crucial for aligning, combining, prioritizing, and filtering inputs across different modalities. Effective integration is central to developing context-aware AI that can make informed decisions based on diverse data sources.7. Storage and Compute Infrastructure
Robust storage solutions and computational resources are essential for managing the large volumes of data generated by multimodal AI systems. High-performance computing (HPC) environments support the intensive processing requirements of these applications.The technologies associated with multimodal AI enable it to create a richer understanding of the world by integrating diverse data types. By leveraging input modules, fusion techniques, NLP, computer vision, audio processing, and effective integration systems, multimodal AI can perform complex tasks that single-modal systems cannot achieve. This capability opens up numerous applications across industries, enhancing human-computer interaction and enabling more intuitive user experiences.
Multimodal stack technologies
Retrieval-augmented generation (RAG) is the foundation of the multimodal AI technology stack. There are a number of different components that come together to provide Input, Fusion, and Output results. With RAG, these components seamlessly interact with each other to provide the complete AI experience.
Natural language processing
Probably the most important advancement in AI has been natural language processing (NLP). With NLP, multimodal AI interacts with data and humans naturally and uses these interactions in conjunction with diverse data types like images, video, sensor data, and much much more. NLP creates a human-computer interaction that wasn’t possible in the past.
Computer vision
NLP opens the AI world to language. Computer vision technologies open the AI world to visual data. With computer vision, AI interprets, understands, and processes visual information like images and videos—summarizing, captioning, or interpreting the visual data in real time. From this, AI creates real-time transcripts or captions for the deaf, or audio interpretation for the blind.
Text analysis
Text analysis works with NLP to understand, process, and generate documents for use in Multimodal AI systems. This is seen in NLP chatbots that use product documentation, emails, or other text-based inputs as training data, generating text-based responses or outputs.
Integration systems
Something required for successful multimodal AI systems is the ability to integrate with external data sources. Leveraging a RAG-based architecture prioritizes this integration and makes integration a core part of the technology stack used by multimodal AI systems.
RAG provides the foundation for bringing in multiple data inputs. RAG distributes the outputs to applications in application-specific structures. This allows legacy-based systems and newly developed applications to integrate seamlessly into the AI process.
Storage and compute
This is probably the broadest-scoped technology in the multimodal AI technology stack. Storage and computing have a critical impact on the development, deployment, and operation of the AI system. When it comes to storage, a multimodal AI system needs the ability to provide data storage, data management, and version control for all of the unique datasets used by the AI system. In addition, it needs significant computation power that can be used for training, real-time data processing, and data optimization.
Traditional environments have brought storage and computing together, but in modern multimodal AI systems, segmentation and virtualization of storage and compute operations provide significant benefits.
What is the difference between multimodal and generative AI?
Terminology in the AI realm can be quite complex, often posing significant challenges due to the vast array of models and technologies involved. Within this expansive field, there are multiple AI models to consider, each with its unique capabilities and applications. Among these, two powerful and distinct types are Generative AI and Multimodal AI.
Generative AI models have surged in popularity recently, largely due to their ability to create new content. These models are trained using existing data, which they analyze to understand patterns and structures. Once trained, Generative AI can produce content that closely resembles the original data it was trained on, whether it's generating realistic images, composing music, or writing text. This capability makes Generative AI particularly valuable in creative industries and applications where the generation of novel and diverse content is essential.
On the other hand, Multimodal AI takes a different approach by focusing on the simultaneous processing and integration of multiple types of data. Instead of being confined to a single data type, like text or images, Multimodal AI systems handle a variety of data inputs at once—such as combining textual, visual, and auditory information. This comprehensive processing capability allows Multimodal AI to achieve a more holistic understanding of complex scenarios, enhancing its ability to interpret and respond to information accurately.
The primary distinction between these two AI models lies in their core functions: while Multimodal AI emphasizes the processing and comprehension of diverse data inputs to form a cohesive understanding, Generative AI excels in identifying patterns within data and leveraging those patterns to generate new, similar content. These complementary capabilities mean that Generative AI can be integrated as one of many output modules within a Multimodal AI framework, providing enriched outputs based on the integrated, multimodal data it processes. This integration highlights the synergistic potential of combining different AI models to create more robust and versatile AI systems.
The Technology Behind Multimodal AI
The core technology that powers multimodal AI involves advanced machine learning algorithms and neural networks capable of processing and integrating different types of data. One key component is the use of Convolutional Neural Networks (CNNs) for image and video data, and Recurrent Neural Networks (RNNs) or Transformers for text and audio data. These models are trained on large datasets that include multiple data types, enabling them to learn the correlations and relationships between different modalities.
Furthermore, attention mechanisms play a crucial role in multimodal AI. They help the model focus on the most relevant parts of the input data, improving the system's efficiency and accuracy. Natural Language Processing (NLP) techniques are also integral, allowing the AI to understand and generate human language in combination with other data forms.
Applications and Real-world Examples
Multimodal AI has a wide range of applications across various industries. In healthcare, it can assist in medical diagnostics by analyzing a combination of medical images, patient records, and genetic data to provide more accurate diagnoses. In the automotive industry, multimodal AI powers advanced driver-assistance systems (ADAS) by integrating data from cameras, radar, and LiDAR sensors to enhance vehicle safety and autonomy.
Another compelling application is in the field of virtual assistants and customer service chatbots. These systems can understand and respond to user queries more effectively by integrating voice recognition, text analysis, and even facial recognition. Real-world examples include Google's Multimodal Transformer model and OpenAI's GPT-3, which can understand and generate text based on various input modalities.
Healthcare
Back in 2020 when Covid 19 was at its peak, we saw a rapid growth of telemedicine. People could meet virtually with physicians to provide safe and expedited personal healthcare. Today, with multimodal AI virtual offices, visits include pictures, text, audio, and video that’s analyzed by an AI physician's assistant. Symptoms from all the different inputs are evaluated and a rapid diagnosis is provided for things like burns, lacerations, rashes, allergic reactions, etc.
We’ve also seen the rise of electronic medical records (EMR) that replace paper folders (with alphabetized last name labels). From there, electronic health records (EHR) efficiently share digital patient records (EMRs) across practices. This digital visibility positively impacts patient care—doctors spend more time treating patients and less time tracking down and managing patient information.
Retail
In retail, multimodal AI provides personalized experiences based on images, video, and text. How many of us have ordered clothing from an online retailer only to realize that it doesn’t look as good as it did in the picture? With multimodal AI, consumers can now upload images/videos of themselves and generate 360 degree views of garments on their bodies. This advancement shows how it fits, looks, and flows in a natural way prior to making the purchase.
Entertainment
Like retail, multimodal AI has the potential to revolutionize the entertainment industry. Content consumers provide multiple input types from personalized content suggestions to real-time gaming content based on gamers’ experiences. Gaming may offer incentives when a player is losing, for example.
With multimodal AI, these games leverage video input of player sentiment to create offers before the players get frustrated and quit playing. Or they tailor the gaming experience based on that sentiment, presenting custom, real-time content that players enjoy.
Multimodal AI and language processing
The possibilities for multimodal AI and language processing are limitless.
Incorporating facial expressions, tone of voice, and other stimuli changes the way we interact with technology.
- Customer service assistants listen to customer support calls and provide real-time analysis of customer frustration levels.
- Manufacturing processes incorporate multimodal AI for tolerance and waste management by incorporating text, video, and imagery.
Multimodal AI changes what technology can do in our lives.
How to use multimodal AI for your business
Addressing challenges might seem overwhelming, but leveraging multimodal AI in business is very achievable with process forethought and by following simple guidelines.
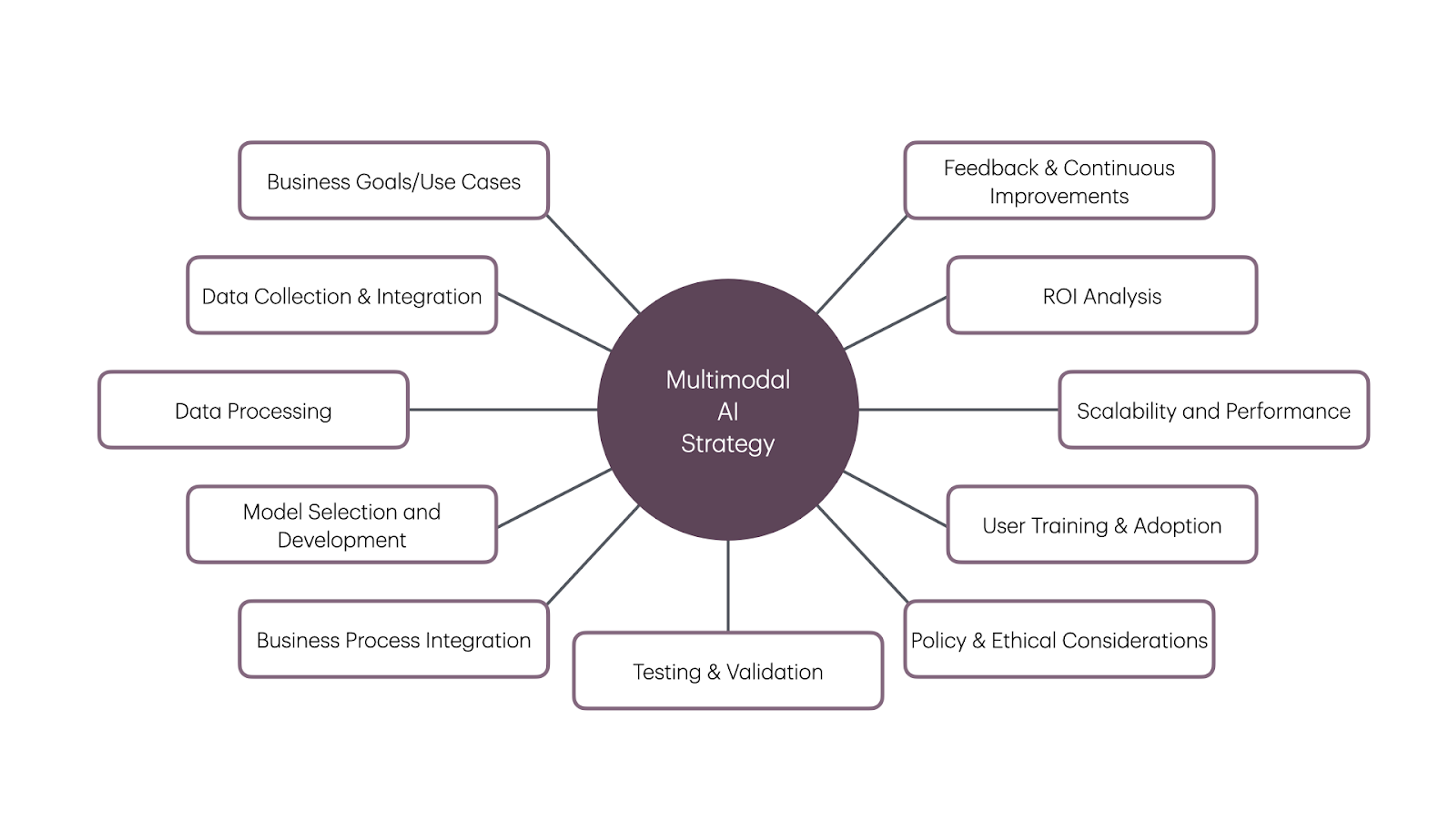
- Identify business goals and use cases: This is the first step in the process. Clearly define why your business should leverage multimodal AI and have a clearly-defined use case that is tangible.
- Data collection and integration: Next, the right approach to data collection and integration is key. One primary question that needs to be asked is “Can and should the data we use be shared across multiple AI applications?” Leveraging an architecture like retrieval-augmented generation (RAG) may be worth the initial investment.
- Data processing: Once you have an approach and you’ve defined inputs, look at how you’ll process data—ultimately defining the fusion model/approach you will use.
- Model selection and development: The other question is whether a general purpose large language model (LLM) is needed? Would a small language model that has been fine-tuned to a specific domain be more appropriate? Most applications should not develop a model from scratch, but leveraging a small language model for domain-specific knowledge can provide value.
- Scalability and performance monitoring: Leveraging multimodal AI within the business takes into account scalability and performance. With massive amounts of data being used to train and prompt multimodal AI systems, monitoring system scalability and performance is required to meet users’ demands, manage costs, and provide predictable response times.
- Integration into business processes: Once the technology decisions have been made, the next layer looks at how responses will integrate into the business process. This is where starting with a RAG approach provides significant benefit, because business processes can be natively-integrated into the workflow.
- Testing and validation: One of the interesting challenges of multimodal AI is the impact inaccurate results have on perception. A human answering random questions with 80% accuracy would be considered pretty good. But a machine with 80% accuracy is considered intolerable. Because of this, testing and Human-in-the-Middle validation is key.
- Privacy and ethical considerations: Another concern that has to be weighed is data sensitivity and the ethical considerations of using specific data. Is the data fed into the AI workflow managed, curated, and protected appropriately to protect the users and consumers of that data? This is where organizations need strong data governance when using data for training AI systems.
- User training and adoption: AI systems in place, proper user training is key to successful adoption. The potential of multimodal AI to change the way an individual works and communicates is massive, but that potential comes with a significant change in how users perform their day to day operations. Being able to showcase productivity improvements by training users how to leverage these new technologies is key to wide-scale adoption.
- Feedback and continuous improvement: Recursive feedback from users and the AI systems is fundamental to providing continuous improvement and more accurate responses. Things like human sentiment, Human-in-the-Middle validation, and response feedback loops, give good AI interactions a vehicle to become great—by integrating real-time feedback on responses and interactions.
- ROI analysis: Lastly to provide real value to the business, there has to be a return on the investment made in multimodal AI. Whether you are in retail, healthcare, logistics, or manufacturing, understanding the business value—and providing metrics on what the business gains by implementing multimodal AI—is fundamental for adoption and growth. AI isn’t right for every problem. Understanding where AI provides value to the business creates space for projects that use AI to be fine-tuned to the use cases that matter.
How does FindErnest integrate computer vision into their multimodal AI solutions?
FindErnest integrates computer vision into its multimodal AI solutions through several innovative approaches, enhancing the capability to analyze and interpret visual data alongside other modalities. Here’s how they achieve this:
Integration of Computer Vision in FindErnest's Multimodal AI Solutions
1. Image and Video Analysis
FindErnest utilizes advanced computer vision techniques to analyze images and videos, extracting meaningful insights that can be combined with other data types. This includes facial recognition, object detection, and anomaly detection, which are essential for applications in security, healthcare, and retail.2. Multimodal Fusion Techniques
The company employs various fusion methods to integrate visual data with other modalities such as text and audio. This can involve:- Early Fusion: Combining raw data from different sources at the initial stages for a unified representation.
- Late Fusion: Processing each modality separately before merging the outputs to enhance decision-making.
- Intermediate Fusion: Using attention mechanisms or deep learning networks to dynamically weigh the importance of different features during integration.
3. Enhanced Contextual Understanding
By integrating computer vision with other modalities, FindErnest's solutions achieve a more comprehensive understanding of context. For example, combining visual inputs with textual descriptions can improve sentiment analysis or scene understanding in applications like customer feedback assessment or automated content generation.4. Robustness Against Input Variability
The integration of computer vision allows FindErnest's systems to be more resilient against noise and variability in input data. For instance, in speech recognition applications, visual cues (like lip movements) can enhance accuracy even when audio quality is poor.5. Customizable Solutions
FindErnest tailors its computer vision capabilities to meet specific business needs, ensuring that the solutions are relevant and effective across various industries. This customization allows clients to leverage visual data in ways that align with their operational goals.6. Real-Time Processing
The company focuses on developing real-time processing capabilities for its multimodal AI solutions, enabling instant analysis of visual data alongside other inputs. This is particularly useful in applications like surveillance systems or interactive customer service platforms.FindErnest effectively integrates computer vision into its multimodal AI offerings by employing advanced fusion techniques, enhancing contextual understanding, and providing customizable solutions tailored to specific industry needs. This integration not only improves the accuracy and robustness of AI applications but also enhances the overall user experience by enabling more natural interactions across different modalities.
