

Discover how Databricks LakeFlow revolutionizes data engineering with its unified and intelligent approach, making data management more efficient and insightful. Ingest data from databases, enterprise apps and cloud sources, transform it in batch and real-time streaming, and confidently deploy and operate in production. In this blog post, we discuss the reasons why we believe LakeFlow will help data teams meet the growing demand for reliable data and AI as well as LakeFlow’s key capabilities integrated into a single product experience.
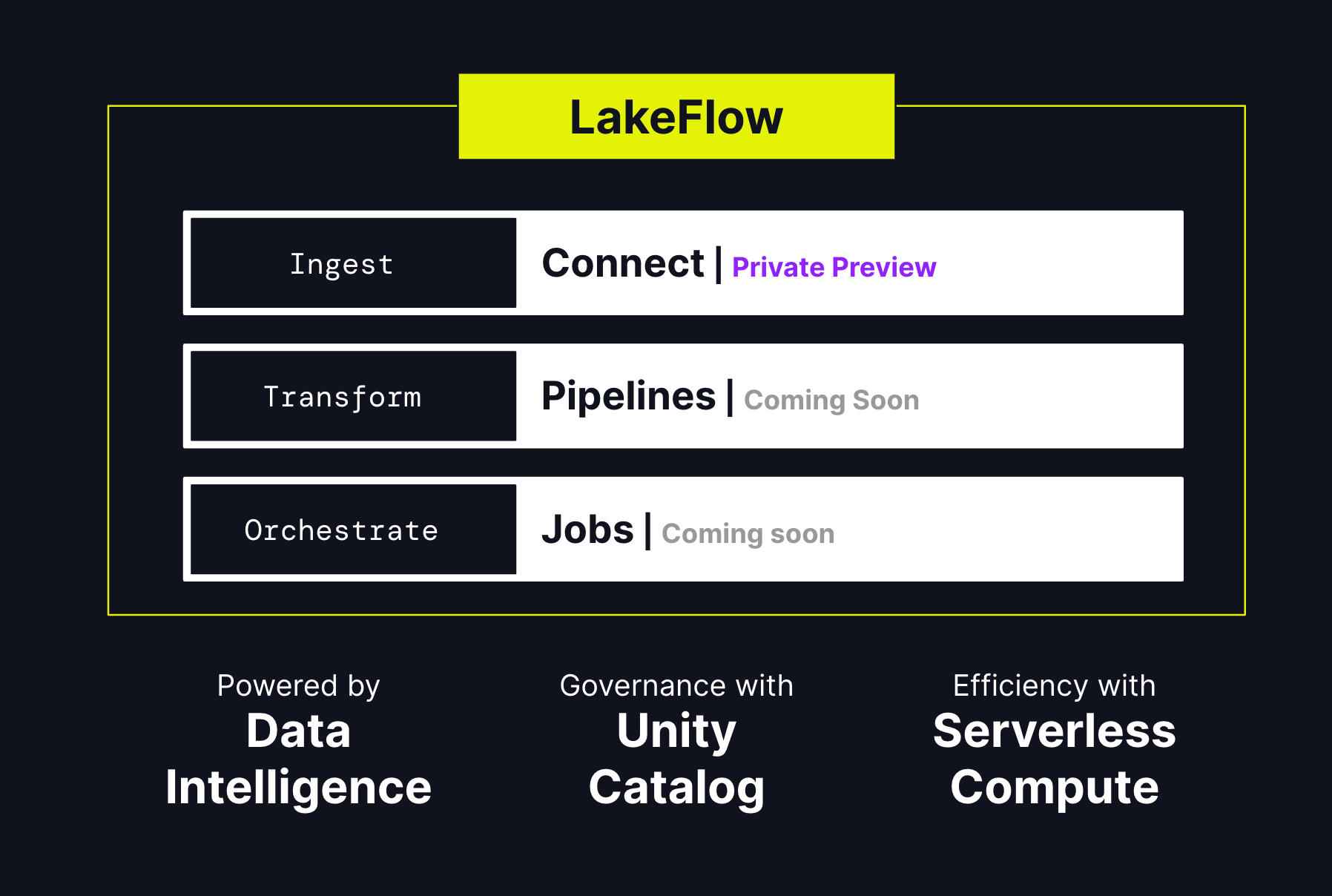
We are thrilled to unveil Databricks LakeFlow, an innovative solution designed to equip you with everything necessary for building and managing production data pipelines. This includes newly developed, highly scalable connectors for databases such as SQL Server and enterprise applications like Salesforce, Workday, Google Analytics, ServiceNow, and SharePoint. Users can perform data transformations in both batch and streaming modes using standard SQL and Python. Additionally, we are introducing Real Time Mode for Apache Spark, enabling stream processing with significantly lower latencies than micro-batch processing. Lastly, you can orchestrate and oversee workflows and deploy them to production using CI/CD. Databricks LakeFlow is fully integrated with the Data Intelligence Platform, offering serverless computing and unified governance through the Unity Catalog.
In this blog post, we discuss the reasons why we believe LakeFlow will help data teams meet the growing demand for reliable data and AI as well as LakeFlow’s key capabilities integrated into a single product experience.
The Evolution of Data Engineering: From Fragmentation to Unity
Data engineering has undergone significant transformations over the years. Initially, organizations relied on fragmented systems and siloed data sources, which often led to inefficiencies and inconsistencies. Managing disparate systems became a daunting task for data engineers, who had to ensure data accuracy and availability while dealing with complex integrations.
The advent of unified data platforms marked a turning point in the industry. These platforms aimed to consolidate data sources, streamline workflows, and provide a single source of truth. Databricks LakeFlow is one such innovative solution, designed to bring coherence and intelligence to data engineering processes.
The Challenges of Data Engineering
Data engineering involves the intricate tasks of collecting, preparing, and managing data to ensure it is high-quality, reliable, and ready for analysis. However, these tasks are fraught with challenges:
- Diverse Data Sources: Businesses frequently need to gather data from numerous systems, each having its formats and access methods. This necessitates the creation and upkeep of specialized connectors for different databases and enterprise applications.
- Batch and Streaming Processing: Handling data in batch and real-time streaming modes requires sophisticated logic for triggering and incremental processing. Latency spikes or failures can disrupt business operations, resulting in significant repercussions.
- Deployment and Monitoring: Implementing scalable data pipelines with CI/CD practices and tracking the quality and lineage of data assets frequently requires extra tools and expertise, adding complexity to the process.
Introducing Databricks LakeFlow: Key Features and Benefits
Databricks LakeFlow provides an extensive array of features designed specifically for the needs of contemporary data engineering. A highlight is its flawless data integration, enabling straightforward ingestion and transformation of data from diverse sources. This ensures that data engineers can handle data that is clean and consistent without needing manual adjustments.
Another significant advantage is its strong orchestration capabilities. LakeFlow facilitates the automation of intricate workflows, decreasing the necessity for manual supervision and lowering the potential for errors. Furthermore, its sophisticated analytics tools deliver insightful data visualizations and predictive models, empowering organizations to efficiently make data-driven decisions.
Databricks LakeFlow stands as a cohesive solution that tackles these challenges directly. It consists of three primary components: LakeFlow Connect, LakeFlow Pipelines, and LakeFlow Jobs, each crafted to simplify and improve various facets of data engineering.
LakeFlow Connect: Simplified Data Ingestion
LakeFlow Connect provides a user-friendly, point-and-click interface for ingesting data from various sources. It supports a wide range of databases such as SQL Server, MySQL, Postgres, and Oracle, as well as enterprise applications like Salesforce, Workday, Google Analytics, and ServiceNow. Additionally, it can ingest unstructured data from sources like SharePoint.
This component leverages Change Data Capture (CDC) technology, acquired through Databricks' acquisition of Arcion, to ensure reliable and efficient data transfer from operational databases to the lakehouse. This approach eliminates the need for fragile and problematic middleware, significantly improving productivity and enabling faster insights.
For example, Insulet, a manufacturer of wearable insulin management systems, uses the Salesforce ingestion connector to streamline its data integration process. By analyzing Salesforce data directly within Databricks, they can deliver updated insights in near-real time, reducing latency from days to minutes.
LakeFlow Pipelines: Efficient Declarative Data Pipelines
LakeFlow Pipelines simplifies the creation and management of data pipelines by leveraging the declarative Delta Live Tables framework. This allows data engineers to write business logic in SQL and Python while Databricks handles data orchestration, incremental processing, and compute infrastructure autoscaling.
Key features of LakeFlow Pipelines include built-in data quality monitoring and Real-Time Mode, which ensures low-latency delivery of time-sensitive datasets without requiring code changes. This enables data teams to focus on developing advanced data engineering solutions rather than dealing with the underlying complexities of data processing.
LakeFlow Jobs: Reliable Orchestration
LakeFlow Jobs provides robust orchestration and monitoring capabilities for production workloads. Built on Databricks Workflows, it can orchestrate any workload, including ingestion, pipelines, notebooks, SQL queries, machine learning training, model deployment, and inference.
This component also offers advanced features like triggers, branching, and looping to meet complex data delivery requirements. It simplifies the tracking of data health and delivery, providing full lineage and relationships between ingestion, transformations, tables, and dashboards. With data freshness and quality monitoring integrated, data teams can ensure the reliability of their data assets.
Built on the Data Intelligence Platform
Databricks LakeFlow is natively integrated with the Databricks Data Intelligence Platform, which provides several foundational capabilities:
- AI-powered Intelligence: Databricks Assistant powers the discovery, authoring, and monitoring of data pipelines, allowing data engineers to build reliable data solutions more efficiently.
- Unified Governance: Integration with Unity Catalog ensures comprehensive data governance, including lineage and data quality management.
- Serverless Compute: This enables the building and orchestration of data pipelines at scale, allowing teams to focus on their work without worrying about infrastructure.
Intelligent Data Management: How LakeFlow Enhances Efficiency
Efficiency is at the core of Databricks LakeFlow's design. The platform leverages machine learning algorithms to optimize data processing tasks, ensuring that resources are used effectively and processes are streamlined. This intelligent approach to data management helps in reducing latency and improving overall system performance.
Furthermore, LakeFlow's intuitive user interface simplifies the management of data pipelines. Data engineers can easily monitor and adjust workflows in real-time, allowing for quick responses to any issues that arise. This level of control and visibility significantly enhances operational efficiency and reduces downtime.
Real-World Applications: Success Stories with Databricks LakeFlow
Many organizations across various sectors have successfully implemented Databricks LakeFlow to revolutionize their data engineering practices. For instance, a leading retail company utilized LakeFlow to consolidate its customer data from multiple touchpoints, resulting in a unified view of customer behaviour and preferences. This enabled the company to tailor its marketing strategies more effectively, leading to increased customer engagement and sales.
In the healthcare industry, a large hospital network adopted LakeFlow to manage patient data more efficiently. By automating data integration and processing tasks, the network was able to reduce administrative burdens on healthcare professionals, allowing them to focus more on patient care. These success stories highlight the transformative potential of Databricks LakeFlow in real-world scenarios.
Future of Data Engineering: The Road Ahead with Databricks LakeFlow
As data volumes continue to grow exponentially, the need for innovative data engineering solutions becomes more critical. Databricks LakeFlow is poised to play a pivotal role in shaping the future of the industry. With ongoing advancements in artificial intelligence and machine learning, LakeFlow is expected to become even more intelligent and adaptive, further enhancing its efficiency and effectiveness.
Looking ahead, Databricks aims to expand the capabilities of LakeFlow by integrating more advanced features such as real-time analytics and enhanced security measures. These developments will ensure that organizations can continue to harness the power of their data while maintaining the highest standards of data integrity and privacy. The future of data engineering looks promising with Databricks LakeFlow leading the way.
Reasons to Select FindErnest for Databricks Lakehouse Solutions
Choosing Findernest for Databricks Lakehouse solutions offers several strategic advantages that can significantly enhance your organization's data management and analytics capabilities. Here are the key reasons to consider Findernest as your partner in implementing Databricks Lakehouse:
1. Expertise in Unified Data Management
Comprehensive Solutions: Findernest specializes in the integration of data lakes and data warehouses, providing a unified platform that simplifies data management. This architecture allows organizations to handle structured, semi-structured, and unstructured data seamlessly, which is essential for modern analytics needs.
Real-Time Analytics: With Databricks Lakehouse, Findernest enables low-latency searches on large datasets, facilitating real-time analytics that empowers businesses to make timely decisions based on current data.
2. Customization and Scalability
Tailored Implementations: Findernest offers customized solutions that align with specific business objectives and industry requirements. This ensures that the Databricks Lakehouse is optimized for your unique data landscape and operational goals.
Scalable Architecture: The platform is designed to scale with your business, accommodating growing data volumes and increasing analytical demands without compromising performance.
3. Advanced Data Processing Capabilities
Integrated ETL Operations: Findernest leverages the integrated data processing features of Databricks Lakehouse to perform efficient ETL (Extract, Transform, Load) operations on a single platform. This reduces the need for multiple tools, streamlining workflows and enhancing productivity.
Support for Machine Learning: The platform supports advanced analytics and machine learning initiatives, allowing organizations to apply AI techniques across all their data effectively.
4. Strong Partnership with Databricks
Official Partnership: As an official partner of Databricks, Findernest has access to the latest technologies, resources, and support from Databricks’ extensive network. This partnership enhances the quality of service provided and ensures that clients benefit from cutting-edge solutions.
Expert Guidance: The expertise gained through this partnership allows Findernest to offer valuable insights and best practices for implementing and optimizing Databricks Lakehouse solutions.
5. Focus on Data Governance and Security
Robust Governance Frameworks: Findernest emphasizes strong data governance practices through the use of Unity Catalog within Databricks Lakehouse. This provides fine-grained access control and ensures compliance with regulatory standards.
Data Security: With a focus on security, Findernest helps organizations protect their data assets while enabling secure data sharing across teams, fostering collaboration without compromising integrity.
6. Comprehensive Support and Training
Ongoing Support Services: Findernest provides continuous support throughout the implementation process and beyond, ensuring that organizations can effectively utilize their Databricks Lakehouse environment.
Custom Training Programs: Tailored training sessions are available to help teams maximize their use of the platform, ensuring that users are well-equipped to leverage its full capabilities.
In summary, choosing Findernest for Databricks Lakehouse solutions means leveraging their expertise in unified data management, customization, advanced processing capabilities, strong partnerships, robust governance practices, and comprehensive support services. This combination positions organizations to achieve significant improvements in their data analytics efforts while driving innovation and efficiency across operations.
